Is Drupal a Disruptive Technology?
What if Harvard College takes on Notre Dame in football. Of course we can beat them; after all, they’re only men. —Professor Harry H. Hansen, Harvard Business School, on understanding the limits of the possible.
There is a lot of talk, some would say hype, about Drupal being enterprise-ready. Certainly Drupal is no piker system. From a relatively unknown Content Management System (CMS), Drupal has burst on the scene and now accounts for one-percent of all websites, which to some might seems small until we stop to think how big the web is. Those in the Drupalsphere are quick point out our successes — whitehouse.gov runs on Drupal, as do scores of other sites with brand names that are household words. My business Partner, Laura Scott, and I have upgraded dozens of existing systems that are undeniably enterprise-level.
I say “systems,” here, because almost by definition, the enterprise-level clients, for better or worse, have been on the internet for some time prior to seeking our help in the move to Drupal. Enterprise-level clients have grown sites over years. Technologies, like geological layers, have been set down over time, depending on historic decisions that changed as time went on. In the year 2000, the Y2K problem surfaced when it was discovered that some legacy software was written in a way that did not allow the date to change from 1999 to 2000, since only the last two digits of the year were programmed to change. The programs, written in the 1960s and 1970s was still in use in 1999 running beneath spiffy new interfaces. Who would have thought mid-20th century software would be running in the year 2000, yet it was. This puts the enterprise-level projects in the category of “most demanding,” as we will see, below, in the Disruptive Technology graph. As a Drupal shop, dealing with legacy systems comes with the territory. For example, in 2007, as pingVision, we migrated Popsci.com from Vignette, a leader in proprietary CMS software, to Drupal 5. The hitch was the Popular Science’s Vingnette database was Oracle and not MySQL, the latter which is standard for the LAMP stack. Moreover, legacy features and already-existing third-party applications required integration of (sometimes) vaguely documented and fluid APIs, all of which is to say that it’s a “jungle out there,” once we get outside of the LAMP Stack.
Linux, Apache, and Bears … oh my!

Drupal has made impressive inroads and in numerous instances has competitors like Vignette. The plucky open source folks have built some superb software built on the bedrock of Linux and are taking on ever-bigger and ever-better.
The entrenched competitors have heard of us, and they are taking notice. We might not dominate today, but mighty oaks grow from acorns and there are those who wonder if Drupal might be up to turning the market upside down, as is the case of a truly disruptive technology. In part one of this article, which appeared on the PINGV Creative website in July, 2010 Drupal Disruptive Open Source: Part I — From Brobdingnag to Lilliput, I addressed the rhetorical question posed by Drupal’s Founder, Dries Buytaert, in his keynote at the 2010 San Francisco Drupalcon: Is Drupal a disruptive technology? Product improves to serve more demanding markets.
The term, “disruptive technology,” was coined by Harvard Business School Professor Clayton Christensen and popularized in his best seller, “The Innovator’s Dilemma.” (ISBN 0-06-662069-4)
In its lowest terms, a disruptor enters a marketplace with an alternative technology and “kills” the leader(s).
The oft-cited classic case-set (one of many examples of disruptive technology) tracks the growth of American minimill steel makers, such as Nucor and Chaparral. Over time steel minimills displaced traditional American steel-makers such as United States Steel and Bethlehem — the integrated mills. The minimills entered the market at the low-end in undemanding applications such as rebar. Over time, and incrementally, the minimills improved their manufacturing technology until they were capable of manufacturing top-quality, high profit, steel. Inasmuch as the minimills had a cost advantage relative to the integrated mills, the traditional steel companies closed their mills and were driven from the market.
LAMP Stack — the Minimill analogy

David Recordon of Facebook in his keynote at the Open Source Convention (OSCON) in July, 2010, addressed the evolution of the LAMP stack. He traced the name, LAMP, back to an article in magazin für computertechnik by Michael Kunze titled “Let There be Light.”
Published in April 1998, an English translation appeared in December of the same year. The tout reads:
Web publishing is hip: Not only the media companies, but also many medium sized and small companies want to make their data available to customers or staff on the net. By choosing freeware components, this can be done in a very budget-friendly way.
The formula is similar to the minimills — it is “budget-friendly” and does not go after the big fish. It pieces together (modular) components that are open source, giving the LAMP stack a cost advantage. One model of disruption asks us to picture Drupal as the market/technology leader (more integrated) and WordPress as a disruptor (less sophisticated). Such an analysis makes sense inasmuch as Drupal is seen as more complicated and more suited to enterprise-level applications. WordPress is emerging with more sophistication, without the perceived “daunting” learning-curve of Drupal. Yet, such a view might be somewhat parochial, for these technologies compete within the LAMP-stack “pond,” just as the minimill steel makers Nucor and Chaparral battled it out in the early rebar days, making steel with the least demanding performance specifications. The LAMP stack has been around for over a dozen years. What else happened in 1998?
- Microsoft launches Windows 98
- Google is founded
- Paypal is founded
- Apple’s iMac is introduced
A lot has happened since then and surely the LAMP stack has evolved, but only now are the limits of the LAMP stack, testing its limits with enterprise systems.
Linux, Apache, MySQL, and PHP … our creed!
“The speed of the whole is the sum of its moving parts.” We all have heard of the Stone Age, the Bronze Age, and the Iron (Steel) Age. Once ships were moved by paddles, later aided by wind, and finally fully by wind. Then came steam powered by coal and later petroleum. Now many are nuclear — though, looking closer, we see steam, internal combustion, and electric motors are still part of the equation. The 19th century was the heyday of mechanical engineering. The 20th century was dominated by electromechanical technology. By the 21st century, engineers have tried to minimize the traditional moving parts, preferring to move electrons and/or pieces at the nano-level. The payoff has been speed and reliability. For the most part, the LAMP stack is rugged and fast, with few moving parts — except for the Tin Man — the servers. This may change as the cost of use of solid-state drives (SSD) declines, but for the time being, even with SSDs, manipulating data remains the rate determining step. That is, in any system, the slowest step determines the over-all speed of the system. The old mainstay of the LAMP stack, MySQL, is being re-examined, more-so than most of the rest of the stack. At one point, MySQL ceases to scale linearly — not just theoretically, but from a practical standpoint in that the data itself is busting from its digital cabinets.
Sharks and Little Fish
Going from Brobdingnag, where everything is larger than Gulliver, to Lilliput, where everything is smaller than Gulliver, has been the story of the electronics revolution. The large contraption gets miniaturized, requires less power to operate, and yet achieves the same amount of output. Microcircuits and microprocessors are at the core of this example. On the other hand, this shrinking in processing power has afforded a low-cost means to preserve a lot data. Creating more and more while getting cheaper and cheaper. My previous article ended with a nod to “big data” and to Enterprise Content Management, ECM. I have linked to the original post for those who are interested, but in short ECM is,
[a] market, with $4 Billion of annual revenue, dominated by a few key players who are acquiring one another through a series of nine- to ten-figure buy-outs. For example IBM paid $1.6 Billion for FileNet. Documentum fetched $1.7 Billion when EMC2 added them to the corporate family. Just recently Open Text gobbled up Vignette to the tune of $321 Million.
It is almost certain that the capitalization of the Drupal ecosystem is small in comparison to the ECM market. Acquia, for example, received $7M of first round financing from North Bridge Venture Partners in 2007 and additional amounts in subsequent rounds. Though a respectable sum, it is dwarfed by the capitalization of the ECM market. The ECM customers are the Fortune 500 and the Dow-Jones 30, so that the number of instances is small compared to the number of Drupal and WordPress websites. However, the cost per enterprise-level site is large in comparison. The ECM suppliers have extensive SEC filings, not to mention press releases and PowerPoint presentations that give us significant insight into the enterprise market-place — and the conventional LAMP-stack would be hard-pressed to meet the requirements of the client-base. From the publicly available material, the “budget-friendly” aspect of the LAMP-stack has not excited the ECM market-place, nor has the benefit of an open source code-based maintained by a solid community.
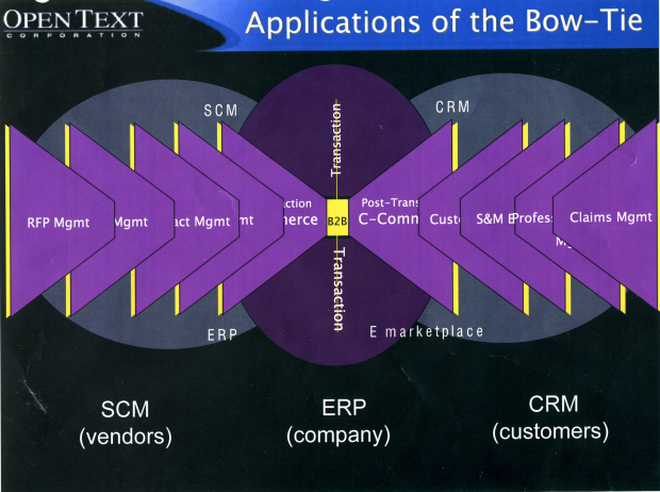
For ECM vendors, the actual sales transaction is small, relative to the what happens before and after. We as consumers — say, going to the mall — are offered a lot of merchandise, much of which we glance at without a second look. Then — something strikes our eye; the quality is good; the price is affordable; we take the purchase to cash-wrap and head to out next destination. But the transaction is only a part of the larger process where the mall store management chooses an item, warehouses it, ships it to store, sets up the display, and sells it – not to mention deals with defectives, returns, and items that simply do not “move.” The enterprise-ready system has two tails — pre-transaction and after-purchase. That is, the purchasing transaction is not much more than an inflection point in the cycle, the “knot” of the bowtie.

The ECM customers do not seem particularly bothered that their software is proprietary, or even customized. The key factor for the client seems to be on-going support all along the business transaction.
LAMP stack as disruptor
Historically the LAMP stack has served a market that for the most part does not have extreme performance criteria, but which is price-sensitive. The margins are not there for the kind of intensive customer service, support, and documentation offered by the ECMs. Briefly, let’s compare and contrast the players and who is serving the high-end and how these deals size up.
The ECM client engagement average is $250,000. About a half the revenues are from Customer Support, a quarter of that is for the software license, and a quarter is service. Maintenance contracts are for one to two years with a large majority being renewed. Annual industry sales in the ECM arena approach $4Billion. With the average deal-sizes of $250,000, that translates into 12,000 deals per year. Some ECMs are said to be making 25% gross margin. Of every revenue dollar, 15% is spent on software development, another 24% is spent on sales & marketing, while 9% is expended on administration. If an ECM firm has annual revenues of $250M, this is equivalent to one thousand deals of $250,000 each, or three six-figure deal every day. SEC files indicate that firms of this revenue level employ about 1,000 people. Finance gurus and technical elves who look at these kinds of breakdowns will point out that the revenue-per-person of this hypothetical ECM is $250,000/employee/year. Billing that out over a man-year means that these firms are billing at the gross-equivalent of $125/hour.
Data gathered by the Lullabots in their article Show Me the Money suggests the better-known Drupal shops are billing at about the same rate — $125/hour, possibly a bit higher. The long-standing Drupal shops are making seven-figures, but few are making eight. That is, a few are breaking $10M annually, and there is no evidence that there are any players making $30M per year. In the Drupal world, the majority, if not all, of the hourly rate will be for implementation — not 15%. A Drupal shop doing $10M annually and billing at $125/hour, would require 38 fulltime coders working 40 hours a week, outside of breaks, lunch, or meetings (that is, 100% billable) to hit that number, which is about 1% of the annual volume of a large player such as Open Text. Put another way, if Open Text writes a $250,000 deal and only 15% is code-related, the coding “burden” is $37,500. At the $125/hour rate, this is a 300 hour coding assignment, a modest sized job for shops that do projects in the 1,000s of hours. And there are more ways that the Drupalsphere is different. There are the vaunted seven-figure-deals, but no shop is getting these on a weekly basis, nor is the Drupal community structured to handle such activity. Put this another way. Assuming a $4B yearly industry revenue with $125/hour average labor rate. This means 32,000,000 labor-hours are devoted to this sector each year. That’s about 15,400 people working 40 hours a week. The value proposition for an enterprise-level site leveraging 32M labor-hours outside itself, is that the client will save even more, inside.
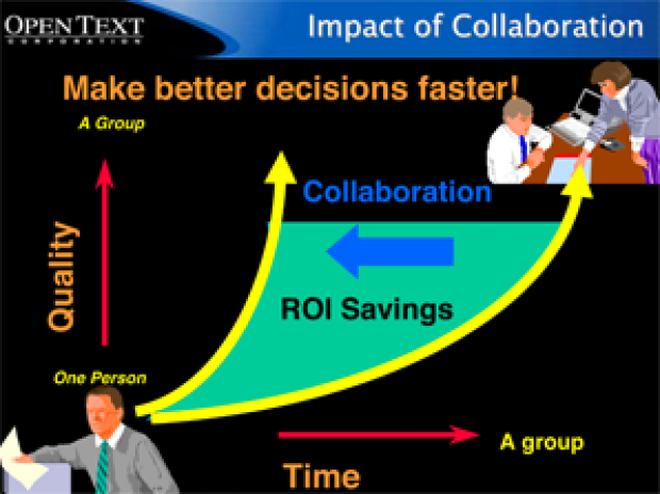
Firms engaging an ECM justify their decision based on Return On Investment (ROI), which translates into increased productivity or other cost-saving measures.
Throughout the era 1950 – 1975, what today we call the Information Technology (IT) group in most businesses was an offshoot of the Accounting Department or the Controller’s office. International Business Machines, IBM, sold hardware with customize software packages to manage unique businesses. As one Harvard Business School classmate explained in Ken Hatten’s “Management of Small Enterprises: Operating Problems,”
You could buy an IBM System 360 that would manage a New Zealand sheep ranch and also could buy [a System 360] to handle selling airplane parts in Seattle. The software would address the different products, but underneath it was pretty much the same basic software, customized and tailored to the end-user’s product or business.
Starting in the mid-1970s, almost as an act of faith, businesses began to invest in business management hardware and software, especially integrated systems. Up to this point, in terms of workflow, departments within a company were largely self-standing, if not quasi-antonymous. For example, a sales department might received a sales order for a specific type of thing, for a certain amount, at a certain price. This order would be manually transmitted to the fulfillment area — a warehouse, assembly line, production facility, what-have-you — and then the shipping department or traffic department would (again) enter in the name, destination, and delivery information. Also, somewhere along the line, invoicing and collecting payment and replenishing raw materials or inventory also took place, the latter usually handled by the purchasing department. Integrating the information into a single system made logical sense, but making it all work required more than logic — it required sustained investment into the business infrastructure. New words entered the lexicon. Some from Japan, like kaizen and kanban. Others, acronyms like JIT — Just In Time — were bandied about. Software, such as ManMan, was introduced by ASK Computers. The lineage of acronyms continued: Material Requirements Planning (MRP) and Manufacturing Resource Planning, (MRP2), which gave way to Advance Planning and Scheduling (ASP) and more recently Enterprise Resource Planning (ERP). Business economists say that for the first five to ten years of this period, businesses continued to invest in systems, not just hardware or software, that would allow them to increase their productivity. By the 1990s, productivity gains of about 20%, sometimes more, were being realized and the faith in the new systems was finally justified, because the productivity increase tended to fall through to the bottom line.
The client firms handle a great many transactions of all shapes, sizes, and forms, and the data generated as part of doing business is growing in proportion to the computing power of the microprocessors running the systems.
From jawbones to backbones
Of late there has been a lot of discussion of “Big Data,” and how to handle it. Big data flows mainly from big business. In the 1980s the patient data at a typical medical facility was legion — cabinets full of handwritten notes recording visits, laboratory results, and x-rays — much of how this was handled was a matter of law and statues, filling room after room. Today a great deal of this information is stored electronically, because it can be. The information highway might be a great idea, but as we have learned with most highways, they soon get clogged and the information highway sometimes seems more like the information traffic jam.
We are learning new numbers. In a recent Reuters article, an author tells us the iPv6 standard will allocate a “trillion, trillion, trillion.” addresses. Wisely, the author did not use the word “unodecillion.”
We have rapidly moved from thinking of data in megabytes to gigabytes to terabytes, and beyond:
- 1,000 terabytes = 1 petabyte
- 1,000 petabytes = 1 exabyte
- 1,000 exabytes = 1 zettabyte
- 1,000 zettabytes = 1 yottabyte
And these numbers are finding their way into the way we measure — sometimes daily,
- Google processes about 24 petabytes of data per day.
- AT&T has about 19 petabytes of data transferred through their networks each day.
- 4 experiments in the Large Hadron Collider will produce about 15 petabytes of data per year, which will be distributed over the LHC Computing Grid.
- The German Climate Computing Center (DKRZ) has a storage capacity of 60 petabytes of climate data.
- As of June 2010, Isohunt has about 10.8 petabytes of files contained in torrents indexed globally.
- The Internet Archive contains about 3 petabytes of data, and is growing at the rate of about 100 terabytes per month as of March, 2009.
- World of Warcraft utilizes 1.3 petabytes of storage to maintain its game.
- The 2009 movie Avatar is reported to have taken over 1 petabyte of local storage at Weta Digital for the rendering of the 3D CGI effects.
In a 1999 website, Roy Williams of Cal Tech, offered that 2 petabytes could hold all US academic research libraries. 200 petabytes could hold all printed material.
Every year the data mass increases 60-percent
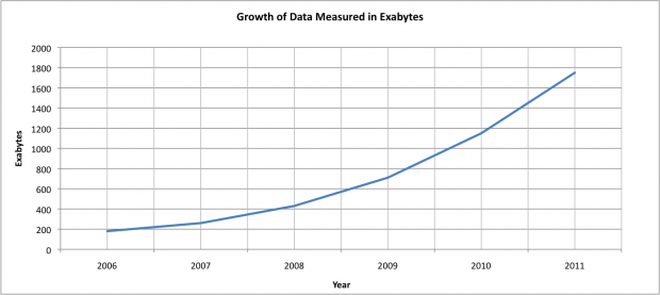
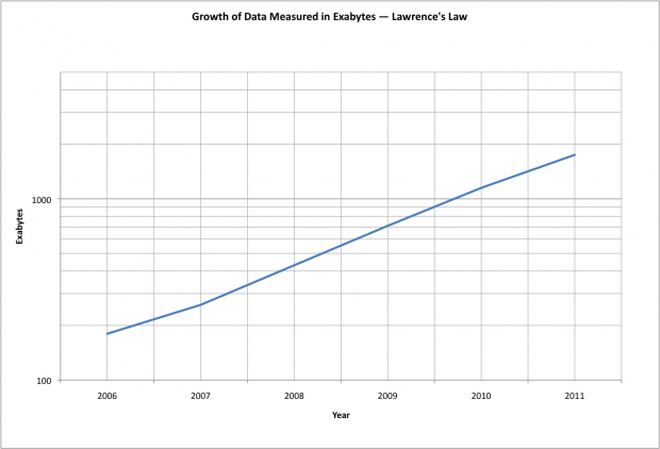
In 2007, the digital universe was 281 exabytes. That is: 281 billion gigabytes, and in that year, for the first time, the data generated exceeded storage capacity. Next year, one prediction says it will be 1,800 billion gigabytes. That is 1.8 zettabytes — a number so unfamiliar that Microsoft Word spellchecker does not recognize it.
A zettabyte is a billion terabytes. The data universe will have increased 10-fold from 2006 to 2011. Taking the 5th root of 10 (fold) gives just under 60% compound growth — we’ll contrast that to Moore’s Law, in a later section.
Not all information created and transmitted gets stored, but by 2011, almost half of the digital universe will not have a permanent home. Fast-growing corners of the digital universe include those related to digital TV, surveillance cameras, Internet access in emerging countries, sensor-based applications, datacenters supporting “cloud computing,” and social networks.
Some call it the Exaflood.

How dire it all is has been debated. Some studies say that data is being generate faster than there is capacity to store it. Others say that this is alarmist, and that there are solution that avert a data storage disaster. It is a valid concern as to whether there is enough storage space, but focusing only on space, and not on retrievability, let alone what problems are in fathoming the relationship of the various datum, can overshadow what the implications, both good and bad, of having so much data with which to deal.
Moore’s Law
In April, 1965, still a relatively unknown physical chemist, Gordon Moore, wrote a three-and-a-half page article in the journal, “Electronics.” The tout said the writer “is one of the new breed of electronic engineers, schooled in the physical sciences rather than in electronics.” Hardly 2000 words in length, it gets right to the point,
The future of integrated electronics is the future of electronics itself. The advantages of integration will bring about a proliferation of electronics, pushing this science into many new areas…. Integrated circuits will lead to such wonders as home computers or at least terminals connected to a central computer, automatic controls for automobiles, and personal portable communications equipment.
But then the enduring insight,
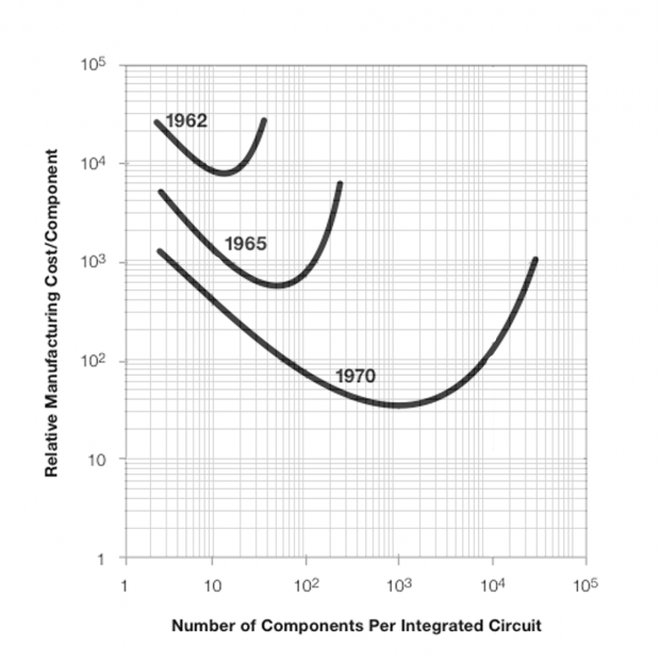
Machines capable of processing data faster will also generate data more quickly. Moore’s Law suggests computer power that grows geometrically will produce data geometrically.
The complexity for minimum component costs has increased at a rate of roughly a factor of two per year
IDC in 2008 provided some data about the growth of data. In a 2008 study, IDC states that from 2006 to 2011 — five years — that data will increase 10-fold.
The venerable LAMP stack
The pressure on the database piece of the LAMP stack is only increasing. The database piece is not only being strained, but it is being rethought.

The LAMP stack is not a monolithic thing, and probably never has been. Andrew Astor in his August, 2005, article, “LAMP’s Dark Side,” says, in part,
[LAMP’s] open source components are well known, readily available, and work well together for many tasks, particularly for serving Web sites without update-intensive database requirements. However, LAMP’s role as a merely illustrative stack of open source offerings is hardly ever acknowledged; in reality, each layer of the LAMP stack is fungible. No one layer was expressly designed to work with the others, and neither do any of them work better with the others than do alternatives. For example, the PostgreSQL and EnterpriseDB databases work just as well with “L,” “A,” and “P” as does MySQL. Similarly acceptable substitutions are, of course, available for each other layer in the stack … … The danger is that this specific software combination will become so institutionalized that an enterprise finding one layer of LAMP unsuitable will end its inquiry, declaring that “the” open source stack cannot meet its needs. That’s bad for Linux, bad for open source software, and bad for enterprises.

Breaking out of the LAMP stack may be inevitable. In a July, 2010, article titled, “The Next LAMP Stack: Hadoop Platform for Big Data Analytics,” author Brett Shepherd writes
Many Fortune 500 and mid-size enterprises are intrigued by Hadoop for Big Data analytics and are funding Hadoop test/dev projects, but would like to see Hadoop evolve into a more fully integrated analytics platform, similar to what the LAMP (Linux, Apache HTTP Server, MySQL and PHP) stack has enabled for web applications. As Michael Dell, founder and chief executive of Dell, told the Financial Times:
We are still in the early stages of our industry in terms of how do organizations take advantage of, and tap into, the power of the information that they have. The IT revolution is just beginning”, May 19, 2010
As the Hadoop data stack becomes more LAMP-like, we get closer to realizing Jim Gray’s vision and giving enterprises an end-to-end analytics platform to unlock the power of their Big Data with the ease of use of a Lotus 1-2-3 or Microsoft Excel spreadsheet.
The early data systems were built around some captive servers and stored what the IT Department was charged to manage, almost Ptolemaic view where, like the universe orbited Earth, everything revolved around the central computer and was very ordered. Today that is no longer the case. There is data and lots and lots of it, and with the web, even quasi-Luddites are searching the web and adding to the collective storage.

To many, if not most people working in Open Source, the “M” in the LAMP stack acronym stands for: MySQL — a so-called Relational Database Management Systems (RDBMS). Traditional RDBMS work well where the data relationships are believed to be well thought out and believed well understood, or at least well-defined.
At one time, it was widely held that the sun, moon, and stars revolved around the Earth, which was the center of the universe; and that system worked. Clocks, seasons, festivals, horoscopes, and navigation all worked with a model of the Earth at the center of all things. The RDBMS related the celestial and physical worlds to a central point of Earth-at-the-center. Snigger though we might today, setting the Earth at the center worked.
Only in 1543, about 50 years after Columbus “discovered” North America, was Copernicus’ “De revolitionibus orbium coelestium” published, and even then, celestial motion was not fully explained. It would be another fifty years, 1598, when Kepler would make his breakthrough and discover planetary orbits were not circular, but elliptical.
One way to think about what these discoverers did was to change the reference frame — the relationships — and for many, this shift did not come easy. In fact, others prior to these individuals, had gone outside of the Ptolemaic system.
Yet, something was happening in the world, where things came together and built upon one another — a recurring pattern in technological breakthroughs to the present day.
This isn’t a question confined just to the LAMP stack or open source. Drupal may well end up being a disruptor of ECMs in so far as it can adapt itself to arcane databases and the other “geological layers” of what has come before. As we saw a decade ago, when Y2K caused consternation and panic in some circles, that what we are given isn’t always what’s pretty, neat, and tidy, or as Emma, the Regent of Japanese-Buddhist hell complained, a ruler can’t always chose his kingdom, meaning every terrain has its immutable rules. Coming full-circle regarding disruption, the LAMP-stack’s next challenge will be the shift from what “plays nice” database-wise, to being an adaptive platform that can interact with large datasets of different types. This takes us deeper into what databases mean and how open source might uniquely play a role.